

Makine öğrenimi, yapay zeka ve veri bilimi nasıl farklı?
Bu üç konuyu anlamak zor olabilir çünkü resmi bir tanım yoktur. Bir yılı aşkın bir süredir makine öğrenimi mühendisi olmama rağmen bu soruya iyi bir cevabım yok. Öyle olduğunu iddia eden herkesten şüphelenirim.
Karışıklığı önlemek için basit tutacağız. Bu makale için, bir şeyi daha fazla anlamak veya gelecekteki bir tür olayı tahmin etmek için makine öğrenimini verilerdeki kalıpları bulma sürecini düşünebilirsiniz.
Aşağıdaki adımlar, bir şey inşa etmeye ve nasıl çalıştığını görmeye yönelik bir önyargıya sahiptir. Yaparak öğrenmek.
Bir Sonraki Makine Öğrenimi Projeniz İçin 6 Adım
Bir makine öğrenimi ardışık düzeni üç ana adıma ayrılabilir. Veri toplama, veri modelleme ve dağıtım. Hepsi birbirini etkiler.
Veri toplayarak bir projeye başlayabilir, modelleyebilir, topladığınız verilerin yetersiz olduğunu fark edebilir, veri toplamaya geri dönebilir, yeniden modelleyebilir, iyi bir model bulabilir, dağıtabilir, çalışmadığını bulabilir, başka bir model yapabilir, dağıtabilirsiniz. tekrar çalışmadığını bulun, veri toplamaya geri dönün. Bu bir döngü.
Bekle, model ne anlama geliyor? konuşlandırmak ne demek? Nasıl veri toplarım?
Harika sorular.
Verileri nasıl topladığınız, probleminize bağlı olacaktır. Bir dakika içinde örneklere bakacağız. Ancak bir yol, müşterinizin bir e-tabloda satın alması olabilir.
Modelleme, toplanan verileriniz içinde içgörürler bulmak için bir makine öğrenimi algoritması kullanmak anlamına gelir.
Normal bir algoritma ile makine öğrenimi algoritması arasındaki fark nedir?
En sevdiğiniz tavuk yemeği için bir yemek tarifi gibi, normal bir algoritma, bir dizi malzemeyi o ballı hardal şaheserine nasıl dönüştüreceğinize dair bir dizi talimattır.
Bir makine öğrenimi algoritmasını farklı kılan şey, talimat setine sahip olmak yerine, malzemelerle ve kullanıma hazır son yemekle başlamanızdır. Makine öğrenimi algoritması daha sonra malzemelere ve son yemeğe bakar ve bir dizi talimat üzerinde çalışır.
Pek çok farklı türde makine öğrenimi algoritması vardır ve bazıları farklı problemlerde diğerlerinden daha iyi performans gösterir. Ancak öncül kalır, hepsinin amacı verilerdeki kalıpları veya talimat setlerini bulmaktır.
Dağıtım, talimat setinizi alıp bir uygulamada kullanmaktır. Bu uygulama, çevrimiçi mağazanızdaki müşterilere ürün önermekten, hastalık varlığını daha iyi tahmin etmeye çalışan bir hastaneye kadar her şey olabilir.
Bu adımların özellikleri her proje için farklı olacaktır. Ancak her birinin içindeki ilkeler benzer kalır.
Bu makale veri modellemeye odaklanmaktadır. Halihazırda veri topladığınızı ve bununla birlikte bir makine öğrenimi kavram kanıtı oluşturmak istediğinizi varsayar. Nasıl yaklaşabileceğinizi çözelim.
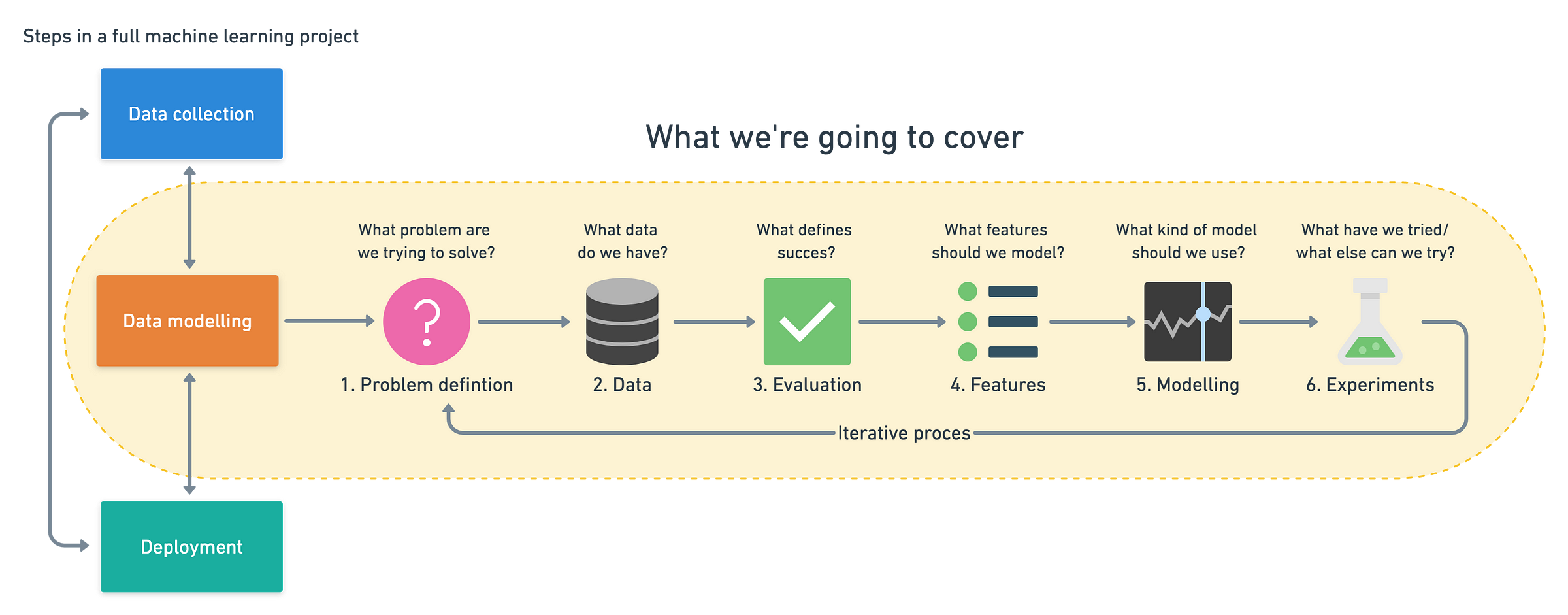 Makine öğrenimi projeleri, veri toplama, veri modelleme ve dağıtım olmak üzere üç adıma ayrılabilir. Bu makale, veri modelleme aşamasındaki adımlara odaklanır ve zaten verileriniz olduğunu varsayar.
Makine öğrenimi projeleri, veri toplama, veri modelleme ve dağıtım olmak üzere üç adıma ayrılabilir. Bu makale, veri modelleme aşamasındaki adımlara odaklanır ve zaten verileriniz olduğunu varsayar.
- Problem Tanımı — Hangi iş problemini çözmeye çalışıyoruz? Bir makine öğrenme problemi olarak nasıl ifade edilebilir?
- Veri — Makine öğrenimi verilerden içgörü alıyorsa, elimizde hangi veriler var? Sorun tanımıyla nasıl eşleşiyor? Verilerimiz yapılandırılmış mı yoksa yapılandırılmamış mı? Statik mi, akış mı?
- Değerlendirme — Başarıyı ne tanımlar? %95 doğru makine öğrenimi modeli yeterince iyi mi?
- Özellikler — Modelimiz için verilerimizin hangi kısımlarını kullanacağız? Zaten bildiklerimiz bunu nasıl etkileyebilir?
- Modelleme — Hangi modeli seçmelisiniz? Nasıl iyileştirebilirsin? Diğer modellerle nasıl karşılaştırırsınız?
- Deney - Başka ne deneyebiliriz? Dağıtılan modelimiz beklediğimiz gibi çalışıyor mu? Diğer adımlar, bulduklarımıza göre nasıl değişiyor?
Her birinde biraz daha derine inelim.
1. Problem Tanımı — İş Probleminizi Bir Makine Öğrenimi Problemi Olarak Yeniden İfade Edin
İşletmenizin makine öğrenimini kullanıp kullanamayacağına karar vermenize yardımcı olmak için ilk adım, bir makine öğrenimi sorununu çözmeye çalıştığınız işletme sorununu eşleştirmektir.
Dört ana makine öğrenimi türü, denetimli öğrenme, denetimsiz öğrenme, transfer öğrenme ve pekiştirmeli öğrenmedir (yarı denetimli öğrenme de vardır, ancak kısa olması için onu dışarıda bıraktım). İş uygulamalarında en çok kullanılan üçü denetimli öğrenme, denetimsiz öğrenme ve transfer öğrenmedir.
Denetimli Öğrenme
Denetimli öğrenme, denetimli olarak adlandırılır çünkü verileriniz ve etiketleriniz vardır. Bir makine öğrenimi algoritması, verilerdeki hangi kalıpların etiketlere yol açtığını öğrenmeye çalışır. Denetlenen kısım eğitim sırasında gerçekleşir. Algoritma yanlış bir etiket tahmin ederse, kendini düzeltmeye çalışır.
Örneğin, yeni bir hastada kalp hastalığını tahmin etmeye çalışıyorsanız. Veri olarak 100 hastanın anonimleştirilmiş tıbbi kayıtlarına ve etiket olarak kalp hastalığı olup olmadığına sahip olabilirsiniz.
Bir makine öğrenimi algoritması, tıbbi kayıtlara (girdiler) ve bir hastanın kalp hastalığı olup olmadığına (çıktılar) bakabilir ve ardından tıbbi kayıtlardaki hangi kalıpların kalp hastalığına yol açtığını bulabilir.
Eğitilmiş bir algoritmaya sahip olduğunuzda, yeni bir hastanın tıbbi kayıtlarını (girdilerini) onun içinden geçirebilir ve kalp hastalığı (çıktı) olup olmadığına dair bir tahmin elde edebilirsiniz. Bu tahminin kesin olmadığını hatırlamak önemlidir. Bir ihtimal olarak geri gelir.
Algoritma, “Daha önce gördüklerime dayanarak, bu yeni hastaların tıbbi kayıtları kalp hastalığı olanlara %70 oranında uyumlu görünüyor” diyor.
Denetimsiz Öğrenme
Denetimsiz öğrenme, verileriniz olduğunda ancak etiketlerinizin olmadığı durumdur. Veriler, çevrimiçi video oyun mağazası müşterilerinizin satın alma geçmişi olabilir. Bu verileri kullanarak, benzer müşterileri bir araya getirerek onlara özel fırsatlar sunabilirsiniz. Müşterilerinizi satın alma geçmişine göre gruplandırmak için bir makine öğrenimi algoritması kullanabilirsiniz.
Grupları inceledikten sonra etiketleri sağlarsınız. Bilgisayar oyunlarıyla ilgilenen bir grup olabilir, konsol oyunlarını tercih eden bir grup ve sadece indirimli eski oyunları satın alan bir grup olabilir. Buna kümeleme denir.
Burada unutulmaması gereken, algoritmanın bu etiketleri sağlamadığıdır. Benzer müşteriler arasındaki kalıpları buldu ve alan bilginizi kullanarak etiketleri sağladınız.
Öğrenimi Aktarın
Transfer öğrenimi, mevcut bir makine öğrenimi modelinin öğrendiği bilgileri alıp kendi probleminize göre ayarlamanızdır.
Bir makine öğrenimi modelini sıfırdan eğitmek pahalı ve zaman alıcı olabilir. İyi haber şu ki, her zaman zorunda değilsin. Makine öğrenimi algoritmaları bir tür veride kalıp bulduğunda, bu kalıplar başka bir veri türünde kullanılabilir.
Diyelim ki bir araba sigortası şirketisiniz ve bir araba kazası için sigorta talebinde bulunan birinin kusurlu olup olmadığını (kazaya neden oldu) veya kusurlu olup olmadığını (kazaya neden olmadı) sınıflandırmak için bir metin sınıflandırma modeli oluşturmak istediniz. ).
Vikipedi’nin tamamını okuyan ve farklı kelimeler arasındaki tüm kalıpları hatırlayan mevcut bir metin modeliyle başlayabilirsiniz, örneğin hangi kelimenin birbiri ardına gelme olasılığı daha yüksektir. Ardından, araba sigortası taleplerinizi (verilerini) sonuçlarıyla (etiketler) kullanarak, mevcut metin modelini kendi probleminize göre ayarlayabilirsiniz.
İşletmenizde makine öğrenimi kullanılabiliyorsa, büyük olasılıkla bu üç öğrenme türünden birine girer.
Ama onları daha fazla sınıflandırma, gerileme ve tavsiyeye ayıralım.
- Sınıflandırma - Bir şeyin bir şey mi yoksa başka bir şey mi olduğunu tahmin etmek ister misiniz? Bir müşterinin çalkalayıp çalmayacağı gibi? Ya da bir hastanın kalp hastalığı olup olmadığı? Dikkat, ikiden fazla şey olabilir. İki sınıfa ikili sınıflandırma, ikiden fazla sınıfa çok sınıflı sınıflandırma denir. Çoklu etiket, bir öğenin birden fazla sınıfa ait olabileceği durumdur.
- Regresyon — Belirli bir sayıda bir şeyi tahmin etmek ister misiniz? Mesela bir ev ne kadara satılacak? Veya gelecek ay sitenizi kaç müşteri ziyaret edecek?
- Tavsiye — Birine bir şey tavsiye etmek ister misiniz? Önceki satın alımlarına göre satın alınacak ürünler gibi mi? Ya da okuma geçmişlerine göre okunacak makaleler?
Artık bunları biliyorsunuz, bir sonraki adımınız iş probleminizi makine öğrenimi terimleriyle tanımlamak.
Daha önceki araba sigortası örneğini kullanalım. Personelinizin okuduğu ve talebi gönderen kişinin kusurlu olup olmadığına karar verdiği her gün binlerce talep alırsınız.
Ancak şimdi taleplerin sayısı, personelinizin üstesinden gelebileceğinden daha hızlı gelmeye başladı. Kusurlu veya kusurlu olarak etiketlenmiş binlerce geçmiş talep örneğiniz var.
Makine öğrenimi yardımcı olabilir mi?
Sen zaten cevabı biliyorsun. Ama bakalım. Bu sorun yukarıdaki üçünden herhangi birine uyuyor mu? Sınıflandırma, regresyon veya öneri?
Yeniden ifade edelim.
Biz, gelen araba sigortası taleplerini kusurlu veya kusurlu olarak sınıflandırmak isteyen bir araba sigortası şirketiyiz.
Anahtar kelimeyi gördünüz mü? Sınıflandırmak.
Görünüşe göre, bu potansiyel olarak bir makine öğrenimi sınıflandırma problemi olabilir. Potansiyel diyorum çünkü çalışmama ihtimali var.
İş probleminizi bir makine öğrenme problemi olarak tanımlamaya gelince, basit başlayın, birden fazla cümle çok fazla. Gerektiğinde karmaşıklık ekleyin.
2. Veri — Makine Öğrenimi Verilerden İçgörü Elde Ediyorsa, Hangi Verilere Sahipsiniz?
Sahip olduğunuz veya toplamanız gereken veriler, çözmek istediğiniz soruna bağlı olacaktır.
Halihazırda verileriniz varsa, büyük olasılıkla iki biçimden birinde olacaktır. Yapılandırılmış veya yapılandırılmamış. Bunların her birinde statik veya akış verileriniz vardır.
- Yapılandırılmış Veriler — Bir satır ve sütun tablosu, müşteri işlemlerinin bir Excel elektronik tablosu, bir hasta kayıtları veritabanı düşünün. Sütunlar ortalama kalp hızı gibi sayısal, cinsiyet gibi kategorik veya göğüs ağrısı yoğunluğu gibi sıralı olabilir.
- Yapılandırılmamış Veriler — Satır ve sütun biçimine hemen yerleştirilemeyen her şey, resimler, ses dosyaları, doğal dil metni.
- Statik Veriler — Değişmesi muhtemel olmayan mevcut geçmiş veriler. Şirketinizin müşteri satın alma geçmişi buna iyi bir örnektir.
- Akış Verileri — Sürekli güncellenen veriler, eski kayıtlar değiştirilebilir, sürekli olarak yeni kayıtlar eklenir.
Örtüşmeler var.
Statik yapılandırılmış bilgi tablonuz, doğal dildeki metin ve fotoğrafları içeren ve sürekli güncellenen sütunlara sahip olabilir.
Kalp hastalığını tahmin etmek için bir sütun cinsiyet, başka bir ortalama kalp hızı, başka bir ortalama kan basıncı, başka bir göğüs ağrısı yoğunluğu olabilir.
Sigorta talebi örneğinde, bir sütun müşterinin talep için gönderdiği metin, bir diğeri metinle birlikte gönderdikleri görüntü ve son sütun talebin sonucu olabilir. Bu tablo, yeni talepler veya eski taleplerin değişen sonuçları ile günlük olarak güncellenir.
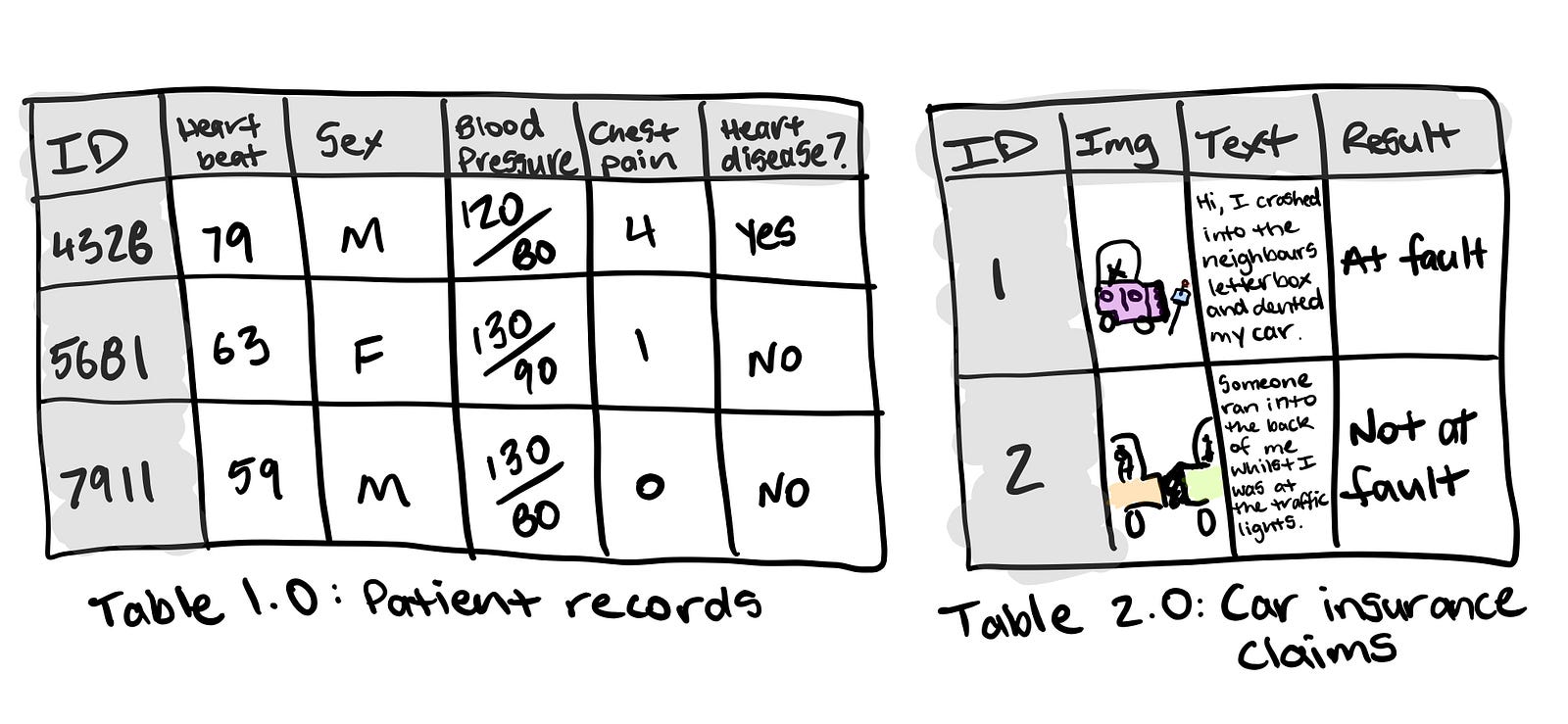 İçinde farklı türde veriler bulunan iki yapılandırılmış veri örneği. Tablo 1.0 sayısal ve kategorik verilere sahiptir. Tablo 2.0, resimler ve doğal dil metinleri içeren yapılandırılmamış verilere sahiptir ancak yapılandırılmış bir şekilde sunulmaktadır.
İçinde farklı türde veriler bulunan iki yapılandırılmış veri örneği. Tablo 1.0 sayısal ve kategorik verilere sahiptir. Tablo 2.0, resimler ve doğal dil metinleri içeren yapılandırılmamış verilere sahiptir ancak yapılandırılmış bir şekilde sunulmaktadır.
İlke kalır. İçgörü kazanmak veya bir şeyi tahmin etmek için sahip olduğunuz verileri kullanmak istiyorsunuz.
Denetimli öğrenme için bu, hedef değişken(ler)i tahmin etmek için özellik değişken(ler)inin kullanılmasını içerir. Kalp hastalığını tahmin etmek için bir özellik değişkeni cinsiyet olabilir ve hedef değişken hastanın kalp hastalığı olup olmadığıdır.
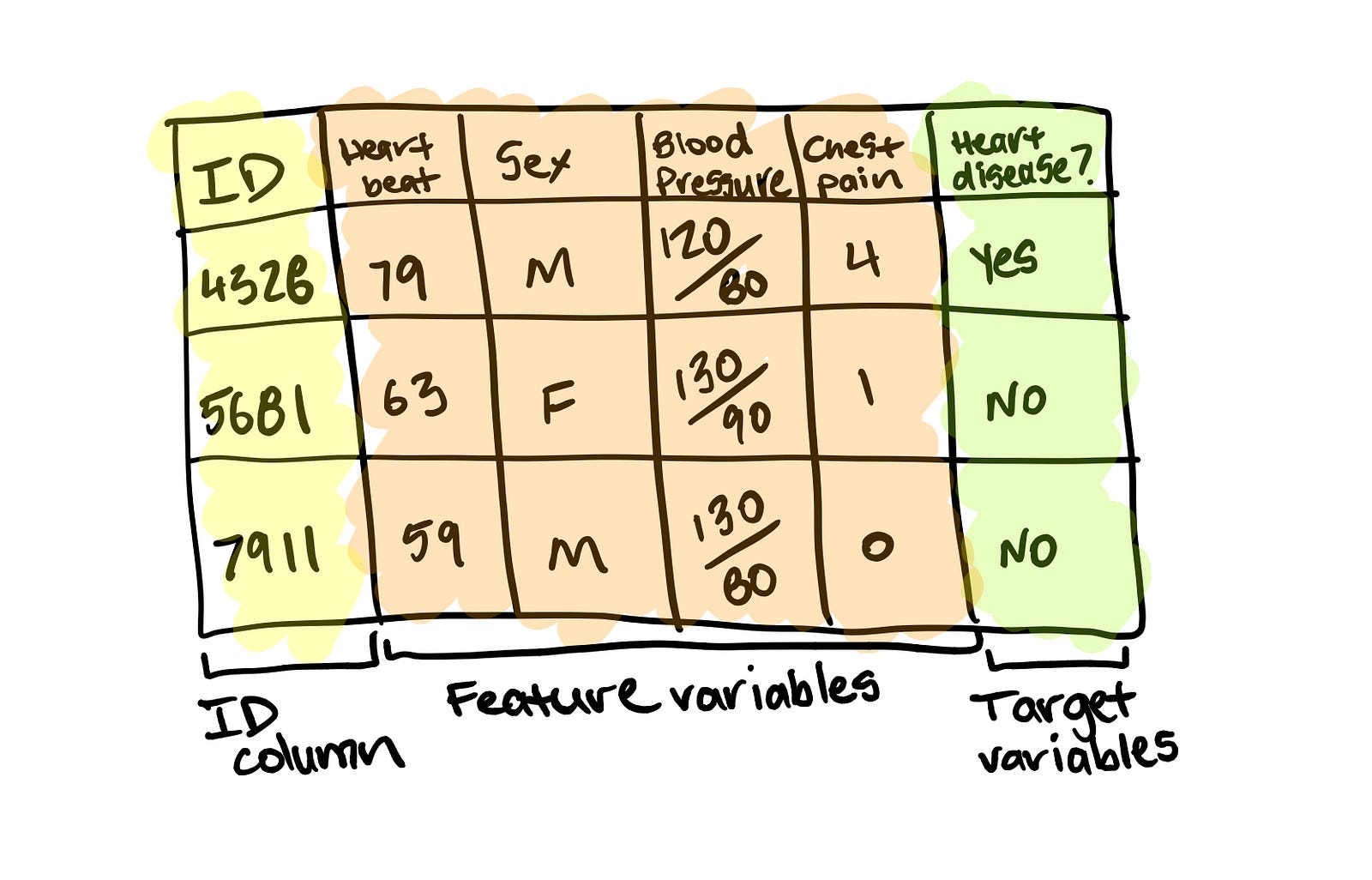 ID sütununa bölünmüş Tablo 1.0 (sarı, makine öğrenimi modeli oluşturmak için kullanılmaz), özellik değişkenleri (turuncu) ve hedef değişkenler (yeşil). Bir makine öğrenimi modeli, özellik değişkenlerindeki kalıpları bulur ve hedef değişkenleri tahmin eder.
ID sütununa bölünmüş Tablo 1.0 (sarı, makine öğrenimi modeli oluşturmak için kullanılmaz), özellik değişkenleri (turuncu) ve hedef değişkenler (yeşil). Bir makine öğrenimi modeli, özellik değişkenlerindeki kalıpları bulur ve hedef değişkenleri tahmin eder.
Denetimsiz öğrenme için etiketleriniz olmaz. Ama yine de kalıpları bulmak isteyeceksiniz. Anlamı, benzer örnekleri gruplamak ve aykırı olan örnekleri bulmak.
Aktarım öğrenimi için, makine öğrenimi algoritmalarının sizinkinden ayrı olarak diğer veri kaynaklarından öğrendiği kalıplardan yararlanmanız dışında, sorununuz denetimli bir öğrenme sorunu olarak kalır.
Bir müşteri verilerini işinizi geliştirmek veya onlara daha iyi bir hizmet sunmak için kullanıyorsanız, bunu onlara bildirmenin önemli olduğunu unutmayın. Bu nedenle, her yerde “bu site çerez kullanıyor” açılır pencerelerini görüyorsunuz. Web sitesi, muhtemelen tekliflerini geliştirmek için bir tür makine öğrenimi ile birlikte siteye nasıl göz attığınızı kullanır.
3. Değerlendirme — Başarıyı Ne Tanımlar? %95 Doğru Makine Öğrenimi Modeli Yeterince İyi Mi?
İş probleminizi makine öğrenimi terimleriyle tanımladınız ve verileriniz var. Şimdi başarıyı neyin tanımladığını tanımlayın.
Sınıflandırma, regresyon ve öneri problemleri için farklı değerlendirme ölçütleri vardır. Hangisini seçeceğiniz hedefinize bağlı olacaktır.
Bu projenin başarılı olması için, modelin birinin hatalı olup olmadığı konusunda %95’in üzerinde doğru olması gerekir.
Bir sigorta talebinde kimin hatalı olduğunu tahmin etmek için %95 doğru bir model kulağa oldukça iyi gelebilir. Ancak kalp hastalığını tahmin etmek için muhtemelen daha iyi sonuçlar isteyeceksiniz.
Sınıflandırma sorunları için dikkate almanız gereken diğer şeyler.
- Yanlış Negatifler - Model negatif, aslında pozitif öngörüyor. E-posta spam tahmini gibi bazı durumlarda, yanlış negatifler endişelenecek kadar fazla değildir. Ancak kendi kendini süren bir araba bilgisayarlı görüş sistemi, bir yaya varken hiçbir yayayı öngörmüyorsa, bu iyi değildir.
- Yanlış Pozitifler - Model pozitif, aslında negatif öngörüyor. Birinin kalp hastalığı olduğunu tahmin etmek, olmadığı halde iyi görünebilir. Güvende olmak daha iyi değil mi? Kişinin yaşam tarzını olumsuz etkiliyorsa veya ihtiyaç duymadığı bir tedavi planına sokuyorsa değil.
- Gerçek Olumsuzlar - Model olumsuz, aslında olumsuz öngörüyor. Bu iyi.
- Gerçek Pozitifler - Model pozitif, aslında pozitif öngörüyor. Bu iyi.
- Kesinlik — Olumlu tahminlerin ne kadarı gerçekten doğruydu? Yanlış pozitif üretmeyen bir modelin hassasiyeti 1.0’dır.
- Hatırlayın - Gerçek pozitiflerin ne kadarı doğru tahmin edildi? Yanlış negatif üretmeyen bir modelin hatırlama değeri 1.0’dır.
- F1 puanı — Kesinlik ve hatırlamanın bir kombinasyonu. 1.0’a ne kadar yakınsa o kadar iyidir.
- Alıcı çalışma karakteristiği (ROC) eğrisi ve Eğrinin altındaki alan (AUC) — ROC eğrisi, gerçek pozitif ve yanlış pozitif oranını karşılaştıran bir grafiktir. AUC metriği, ROC eğrisinin altındaki alandır. Tahminleri %100 yanlış olan bir modelin AUC değeri 0.0, tahminleri %100 doğru olan bir modelin AUC değeri 1.0’dır.
Regresyon problemleri için (bir sayıyı tahmin etmek istediğiniz yerde), modelinizin tahmin ettiği ile gerçek değer arasındaki farkı en aza indirmek isteyeceksiniz. Bir evin satacağı fiyatı tahmin etmeye çalışıyorsanız, modelinizin gerçek fiyata mümkün olduğunca yakın olmasını istersiniz. Bunu yapmak için MAE veya RMSE kullanın.
- Ortalama mutlak hata (MAE) — Modelinizin tahminleri ile gerçek sayılar arasındaki ortalama fark.
- Ortalama kare hatası (RMSE) — Modelinizin tahminleri ile gerçek sayılar arasındaki kare farklarının ortalamasının karekökü.
Büyük hataların daha önemli olmasını istiyorsanız RMSE kullanın. Örneğin, bir evin 200.000$ yerine 300.000$’dan satılacağını tahmin etmek ve 100.000$ ekside olmak 50.000$ kapalı olmaktan iki kat daha kötüdür. Veya MAE, 100.000 $ ile kapalı olmak, 50.000 $ ile kapalı olmaktan iki kat daha kötüyse.
Öneri problemlerinin deneyde test edilmesi daha zordur. Bunu yapmanın bir yolu, verilerinizin bir kısmını alıp saklamaktır. Modeliniz oluşturulduğunda, gizli veriler için önerileri tahmin etmek ve nasıl hizalandığını görmek için bunu kullanın.
Çevrimiçi mağazanızda müşterilere ürün önermeye çalıştığınızı varsayalım. 2010–2019 arasındaki geçmiş satın alma verileriniz var. 2010–2018 verileri üzerine bir model oluşturabilir ve ardından 2019 satın alımlarını tahmin etmek için kullanabilirsiniz. O zaman bu bir sınıflandırma sorunu haline gelir çünkü birisinin bir ürünü satın alma olasılığının olup olmadığını sınıflandırmaya çalışıyorsunuz.
Ancak, geleneksel sınıflandırma metrikleri, öneri sorunları için en iyisi değildir. Kesinlik ve geri çağırma, sipariş kavramına sahip değildir.
Makine öğrenimi modeliniz, web sitenizde bir müşteriye gösterilecek 10 öneriden oluşan bir liste döndürdüyse, en iyilerinin ilk önce görüntülenmesini isterdiniz, değil mi?
- Hassasiyet @ k (k’ye kadar hassasiyet) — Normal hassasiyetle aynı, ancak k kesme değerini siz seçersiniz. Örneğin, 5’te kesinlik, yalnızca ilk 5 tavsiyeyi önemsediğimiz anlamına gelir. 10.000 ürününüz olabilir. Ancak hepsini müşterilerinize tavsiye edemezsiniz.
Başlangıç
4. Özellikler — Verileriniz Hangi Özelliklere Sahiptir ve Modelinizi Oluşturmak İçin Hangilerini Kullanabilirsiniz?
Tüm veriler aynı değildir. Birinin özelliklerden bahsettiğini duyduğunuzda, veriler içindeki farklı veri türlerinden bahsediyorlardır.
Üç ana özellik türü kategorik, sürekli (veya sayısal) ve türetilmiştir.
- Kategorik Özellikler — Biri veya diğeri(ler). Örneğin kalp hastalığı sorunumuzda hastanın cinsiyeti. Veya bir çevrimiçi mağaza için, birisinin satın alma işlemi yapıp yapmadığı.
- Sürekli (veya sayısal) Özellikler — Ortalama kalp atış hızı veya oturum açma sayısı gibi sayısal bir değer.
- Türetilmiş Özellikler — Verilerden oluşturduğunuz özellikler . Genellikle özellik mühendisliği olarak adlandırılır. Özellik mühendisliği, bir konu uzmanının bilgilerini nasıl alıp verilere kodladığıdır. Son girişten bu yana geçen süre olarak adlandırılan bir özellik oluşturmak için giriş yapma sayısını zaman damgalarıyla birleştirebilirsiniz. Veya sayıları rakamlardan “hafta içi (evet)” ve “hafta içi (hayır)”a çevirin.
Metin, resimler ve hayal edebileceğiniz hemen hemen her şey de bir özellik olabilir. Ne olursa olsun, bir makine öğrenme algoritması onları modellemeden önce hepsi sayılara dönüştürülür.
Özellikler söz konusu olduğunda hatırlanması gereken bazı önemli şeyler.
- Deney (eğitim) ve üretim (test) sırasında bunları aynı tutun – Bir makine öğrenimi modeli, gerçek bir sistemde ne için kullanılacağına mümkün olduğunca yakın olan özellikler üzerinde eğitilmelidir.
- Konu uzmanlarıyla çalışın — Sorun hakkında zaten ne biliyorsunuz, bu, kullandığınız özellikleri nasıl etkileyebilir? Makine öğrenimi mühendislerinizin ve veri bilimcilerinizin bunu bilmesini sağlayın.
- Buna değerler mi? — Numunelerinizin sadece %10’unda bir özellik varsa, onu bir modele dahil etmeye değer mi? En fazla kapsama sahip özellikleri tercih edin. Çok sayıda örneğin verisi olanlar.
- Mükemmel eşittir bozuk — Modeliniz mükemmel performans gösteriyorsa, muhtemelen bir yerde özellik sızıntısı var demektir. Bu, modelinizin üzerinde eğitim aldığı verilerin onu test etmek için kullanıldığı anlamına gelir. Hiçbir model mükemmel değildir.
Basit bir temel ölçü oluşturmak için özellikleri kullanabilirsiniz. Müşteri kaybı konusunda bir konu uzmanı, birisinin 3 hafta giriş yapmadıktan sonra üyeliğini iptal etme olasılığının %80 olduğunu biliyor olabilir.
Veya evlerin satış fiyatlarını bilen bir emlakçı, 5’ten fazla yatak odası ve 4 banyosu olan evlerin 500.000 dolardan fazla sattığını biliyor olabilir.
Bunlar basitleştirilmiştir ve kesin olmaları gerekmez. Ancak, makine öğreniminin geliştirilip geliştirilmeyeceğini görmek için kullanacağınız şey budur.
5. Modelleme — Hangi Modeli Seçmelisiniz? Nasıl İyileştirebilirsiniz? Diğer Modellerle Nasıl Karşılaştırırsınız?
Probleminizi tanımladıktan, verilerinizi, değerlendirme kriterlerinizi ve özelliklerinizi hazırladıktan sonra modelleme zamanı.
Modelleme, model seçme, model geliştirme, diğerleriyle karşılaştırma olmak üzere üç kısma ayrılır.
Model Seçimi
Bir model seçerken, dikkate almak isteyeceksiniz, yorumlanabilirlik ve hata ayıklama kolaylığı, veri miktarı, eğitim ve tahmin sınırlamaları.
- Yorumlanabilirlik ve hata ayıklama kolaylığı — Bir model neden aldığı kararı verdi? Hatalar nasıl düzeltilebilir?
- Veri miktarı — Ne kadar veriniz var? Bu değişecek mi?
- Eğitim ve tahmin sınırlamaları - Bu, yukarıdakilerle bağlantılıdır, eğitim ve tahmin için ne kadar zamanınız ve kaynağınız var?
Bunları ele almak için basit başlayın. Son teknoloji ürünü bir modele ulaşmak cazip gelebilir. Ancak, eğitim için 10 kat işlem kaynağı gerekiyorsa ve değerlendirme metriğinizde %2’lik bir artış için tahmin süreleri 5 kat daha uzunsa, bu en iyi seçim olmayabilir.
Lojistik regresyon gibi doğrusal modellerin yorumlanması genellikle daha kolaydır, eğitim için çok hızlıdır ve sinir ağları gibi daha derin modellerden daha hızlı tahminde bulunur.
Ancak büyük olasılıkla verileriniz gerçek dünyadandır. Gerçek dünyadan gelen veriler her zaman doğrusal değildir.
Sonra ne?
Karar ağaçları ve gradyan destekli algoritmalar (süslü kelimeler, şu an için önemli olmayan tanımlar) toplulukları, genellikle Excel tabloları ve veri çerçeveleri gibi yapılandırılmış veriler üzerinde en iyi sonucu verir. İçine bak rastgele ormanlar , XGBoost ve CatBoost .
Sinir ağları gibi derin modeller genellikle en iyi şekilde görüntüler, ses dosyaları ve doğal dildeki metinler gibi yapılandırılmamış veriler üzerinde çalışır. Bununla birlikte, değiş tokuş, eğitimlerinin genellikle daha uzun sürmesi, hata ayıklamanın daha zor olması ve tahmin süresinin daha uzun sürmesidir. Ancak bu, onları kullanmamanız gerektiği anlamına gelmez.
Transfer öğrenme, derin modellerden ve doğrusal modellerden yararlanan bir yaklaşımdır. Önceden eğitilmiş bir derin model almayı ve öğrendiği kalıpları doğrusal modelinize girdi olarak kullanmayı içerir. Bu, eğitim süresinden önemli ölçüde tasarruf sağlar ve daha hızlı deneme yapmanızı sağlar.
Önceden eğitilmiş modelleri nerede bulabilirim?
Önceden eğitilmiş modeller PyTorch hub , TensorFlow hub , model hayvanat bahçesinde ve fast.ai çerçevesinde mevcuttur . Bu, herhangi bir kavram kanıtı oluşturmak için ilk önce bakmak için iyi bir yerdir.
Diğer tür modeller ne olacak?
Bir kavram kanıtı oluşturmak için, kendi makine öğrenimi modelinizi oluşturmanız pek olası değildir. İnsanlar zaten bunlar için kod yazdılar.
Odaklanacağınız şey, girdilerinizi ve çıktılarınızı mevcut bir modelle kullanılabilecek şekilde hazırlamaktır. Bu, verilerinizin ve etiketlerinizin kesin olarak tanımlanması ve hangi sorunu çözmeye çalıştığınızı anlamanız anlamına gelir.
 Başlangıç
Başlangıç
Bir Modeli Ayarlama ve Geliştirme
Bir modelin ilk sonuçları onun son sonuçları değildir. Bir arabanın ayarlanması gibi, makine öğrenimi modelleri de performansı artıracak şekilde ayarlanabilir.
Bir modelin ayarlanması, öğrenme hızı veya optimize edici gibi hiperparametrelerin değiştirilmesini içerir. Veya rastgele ormanlar için ağaç sayısı ve sinir ağları için katman sayısı ve türü gibi modele özgü mimari faktörler.
Bunlar, bir uygulayıcının elle ayarlaması gereken bir şeydi, ancak giderek daha fazla otomatik hale geliyor. Ve mümkün olan her yerde olmalıdır.
Aktarım yoluyla öğrenme yoluyla önceden eğitilmiş bir modelin kullanılması, çoğu zaman tüm bu adımların ek yararına sahiptir.
Modellerin ayarlanması ve iyileştirilmesi için öncelik, tekrarlanabilirlik ve verimlilik olmalıdır. Birisi, performansı artırmak için attığınız adımları yeniden üretebilmelidir. Ve ana darboğazınız geliştirilecek yeni fikirler değil, model eğitim süresi olacağından, çabalarınız verimliliğe yönelik olmalıdır.
Modelleri Karşılaştırma
Elmaları elmalarla karşılaştırın.
- Model 1, X verisi üzerinde eğitildi, Y verisi üzerinde değerlendirildi.
- Model 2, X verisi üzerinde eğitildi, Y verisi üzerinde değerlendirildi.
Model 1 ve 2’nin değişebildiği, ancak X verilerinin veya Y verilerinin değişemediği durumlarda.
6. Deney — Başka Ne Deneyebiliriz? Diğer Adımlar, Bulduklarımıza Göre Nasıl Değişiyor? Dağıtılan Modelimiz Beklediğimiz Gibi Çalışıyor mu?
Bu adım, diğer tüm adımları içerir. Makine öğrenimi oldukça yinelemeli bir süreç olduğundan, deneylerinizin uygulanabilir olduğundan emin olmak isteyeceksiniz.
En büyük hedefiniz, çevrimdışı denemeler ile çevrimiçi denemeler arasındaki süreyi en aza indirmek olmalıdır.
Çevrimdışı denemeler, projeniz henüz müşteriye dönük olmadığında attığınız adımlardır. Çevrimiçi deneyler, makine öğrenimi modeliniz üretimdeyken gerçekleşir.
Tüm deneyler, verilerinizin farklı kısımları üzerinde yapılmalıdır.
- Eğitim Veri Seti — Model eğitimi için bu seti kullanın, verilerinizin %70-80’i standarttır.
- Doğrulama/Geliştirme Veri Seti — Model ayarlama için bu seti kullanın, verilerinizin %10-15’i standarttır.
- Test Veri Seti — Model testi ve karşılaştırması için bu seti kullanın, verilerinizin %10-15’i standarttır.
Bu miktarlar, probleminize ve sahip olduğunuz verilere bağlı olarak biraz dalgalanabilir.
Eğitim verilerindeki düşük performans, modelin doğru şekilde öğrenilmediği anlamına gelir. Farklı bir model deneyin, mevcut olanı iyileştirin, daha fazla veri toplayın, daha iyi veri toplayın.
Test verilerindeki düşük performans, modelinizin iyi genelleme yapmadığı anlamına gelir. Modeliniz eğitim verilerine fazla uyuyor olabilir. Daha basit bir model kullanın veya daha fazla veri toplayın.
Bir kez konuşlandırıldıktan sonra (gerçek dünyada) düşük performans, modelinizi eğittiğiniz ve test ettiğiniz şey ile gerçekte neler olduğu arasında bir fark olduğu anlamına gelir. 1. ve 2. adımı tekrar gözden geçirin. Verilerinizin çözmeye çalıştığınız sorunla eşleştiğinden emin olun.
Büyük bir deneysel değişiklik uyguladığınızda, neyin ve nedenini belgeleyin. Unutmayın, model ayarlama gibi, gelecekteki benliğiniz de dahil olmak üzere birisi yaptığınız şeyi yeniden üretebilmelidir.
Bu, güncellenen modelleri ve güncellenen veri kümelerini düzenli olarak kaydetmek anlamına gelir.
Kavram Kanıtı Olarak Bir Araya Getirmek
Birçok işletme makine öğrenimini duymuştur ancak nereden başlayacağından emin değildir. Başlamak için en iyi yerlerden biri, bir kavram kanıtı oluşturmak için yukarıdaki altı adımı kullanmaktır.
Kavram kanıtı, işletmenizin çalışma şeklini temelden değiştirecek bir şey olarak değil, makine öğreniminin işletmenize değer katıp getiremeyeceğine dair bir keşif olarak görülmelidir.
Ne de olsa, yutturmacaya ayak uydurmak için süslü çözümlerin peşinde değilsiniz. Değer katan çözümlerin peşindesiniz.
Kavram kanıtına bir zaman çizelgesi koyun, 2, 6 ve 12 hafta iyi miktarlardır. İyi verilerle, iyi bir makine öğrenimi ve veri bilimi uygulayıcısı, nispeten küçük bir zaman diliminde nihai modelleme sonuçlarının %80-90’ını elde edebilir.
Konu uzmanlarınızın, makine öğrenimi mühendislerinizin ve veri bilimcilerinizin birlikte çalışmasını sağlayın. Yanlış şeyi modelleyen harika bir model oluşturan bir makine öğrenimi mühendisinden daha kötü bir şey yoktur.
Bir web tasarımcısı, bir makine öğrenimi deneyine yardımcı olmak için bir çevrimiçi mağazanın düzenini iyileştirebilirse, bunu bilmelidir.
Kavramların kanıtlanmasının doğası gereği, makine öğreniminin işletmenizin yararlanabileceği bir şey olmadığı (olasılıkla) ortaya çıkabileceğini unutmayın. Bir proje yöneticisi olarak bunun farkında olduğunuzdan emin olun. Bir makine öğrenimi mühendisi veya veri bilimcisi iseniz, sonuçlarınızın hiçbir yere gitmeyeceğini kabul etmeye istekli olun.
Ama hepsi kaybolmaz.
Çalışmayan bir şeyin değeri, artık neyin işe yaramadığını biliyor olmanız ve çabalarınızı başka bir yere yönlendirebilmenizdir. Bu nedenle deneyler için bir zaman çerçevesi belirlemek faydalıdır. Asla yeterli zaman yoktur, ancak teslim tarihleri
Bir makine öğrenimi kavramı kanıtı iyi çıkıyorsa, bir adım daha atın, değilse geri adım atın. Yaparak öğrenmek, bir şey hakkında düşünmekten daha hızlı bir süreçtir.
